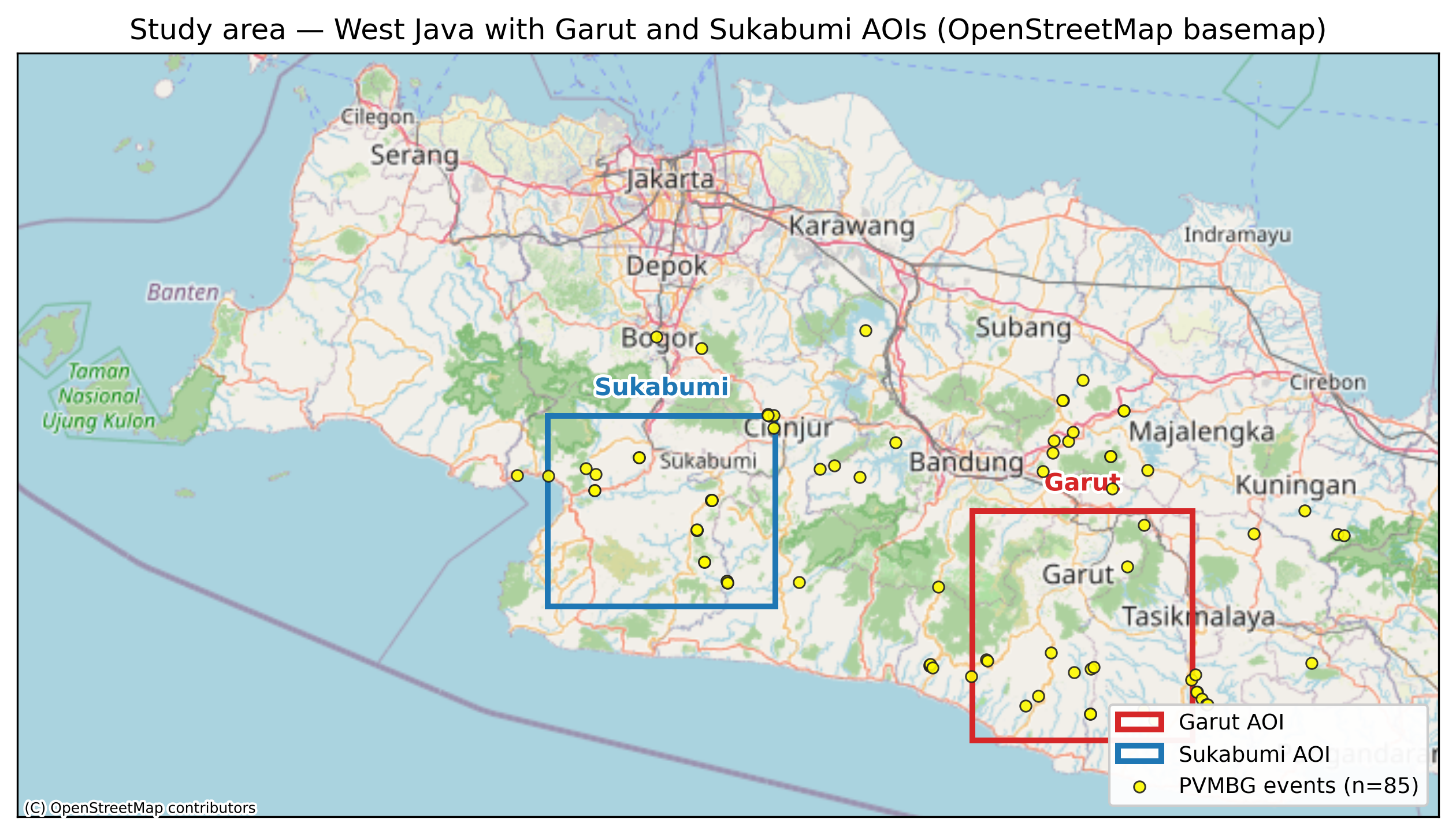
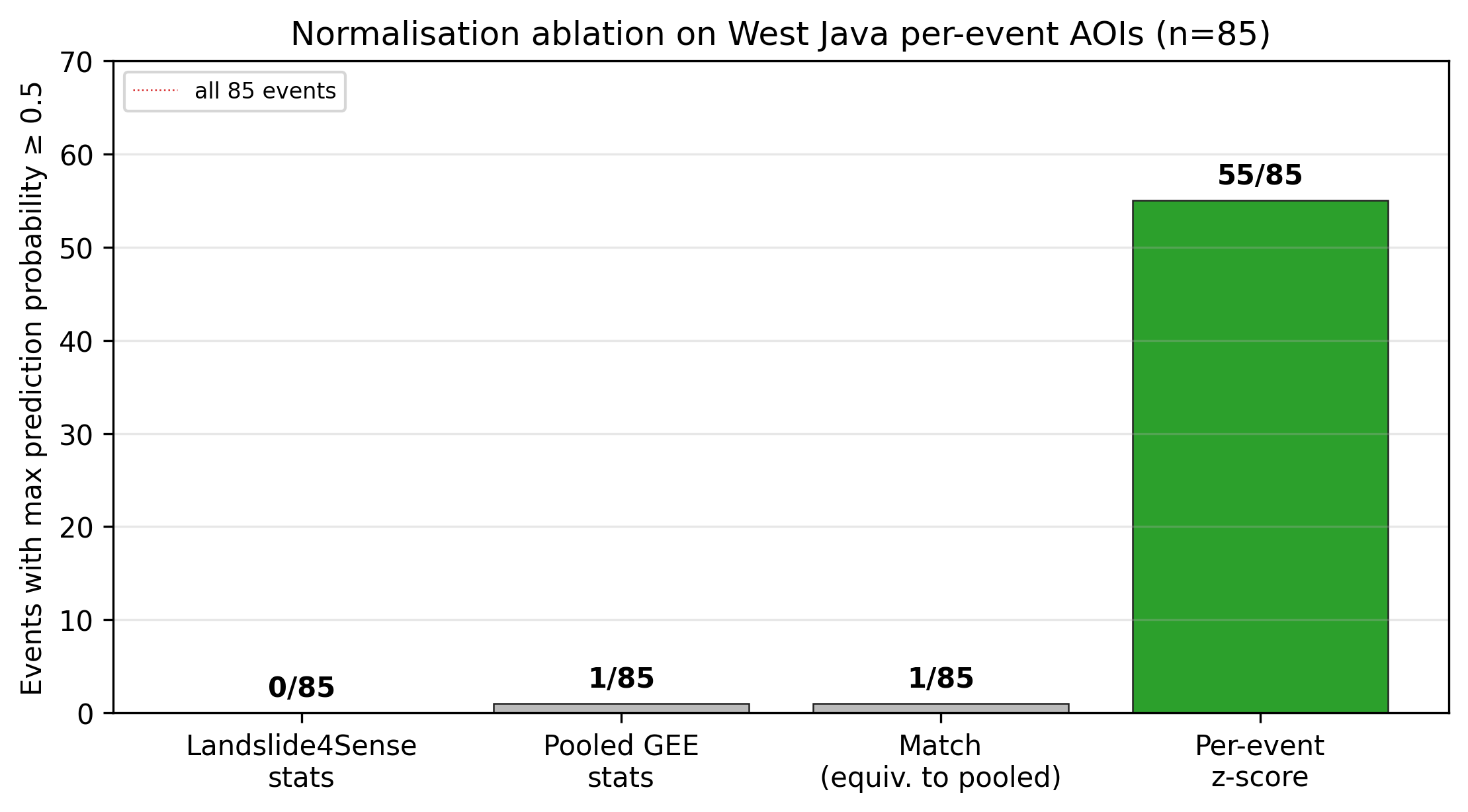
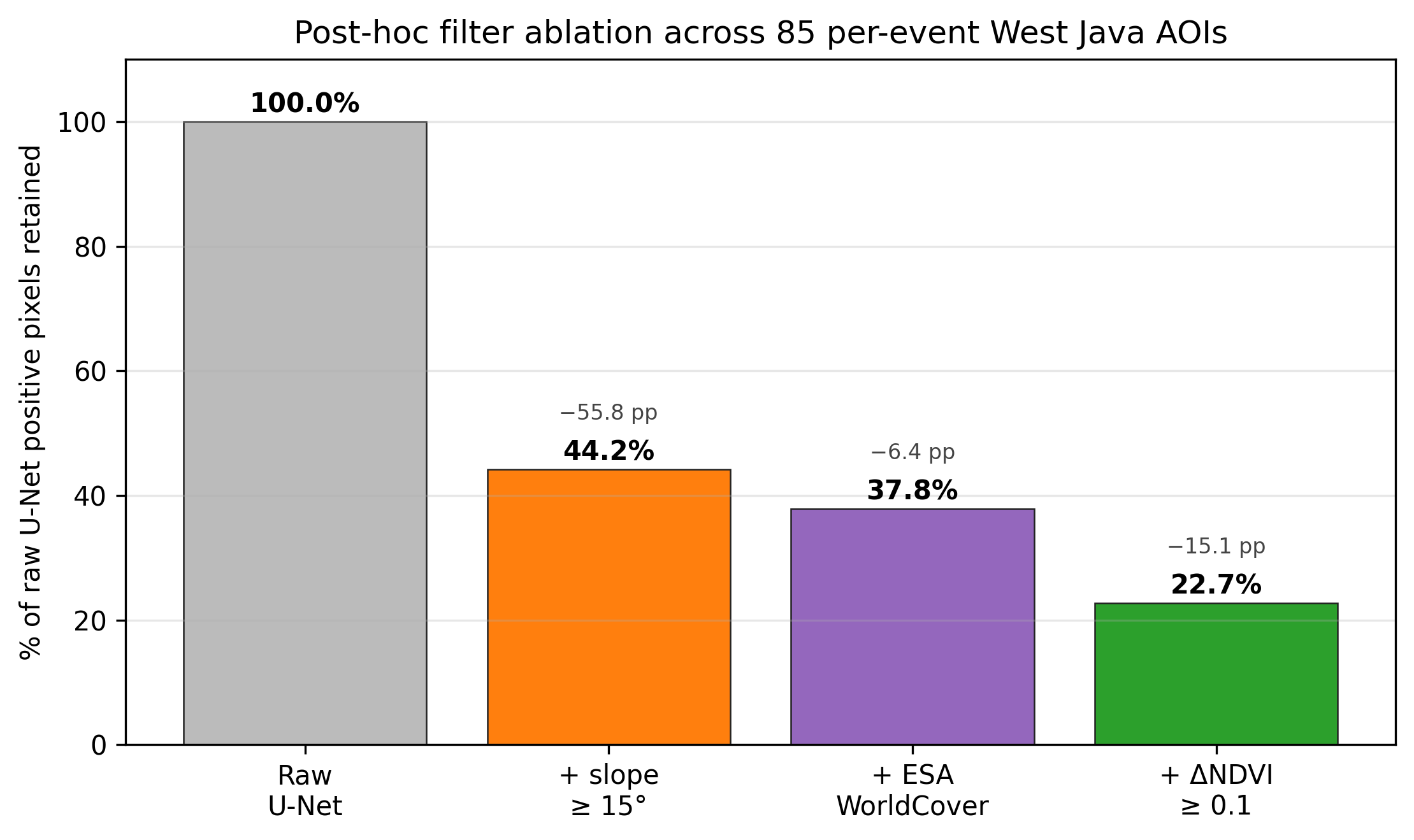
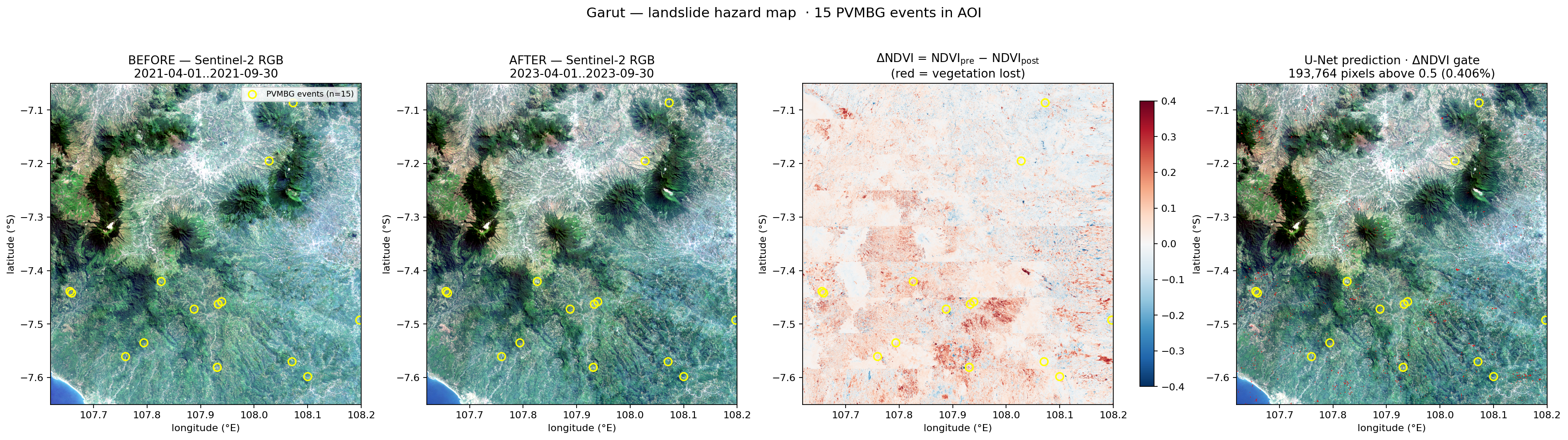
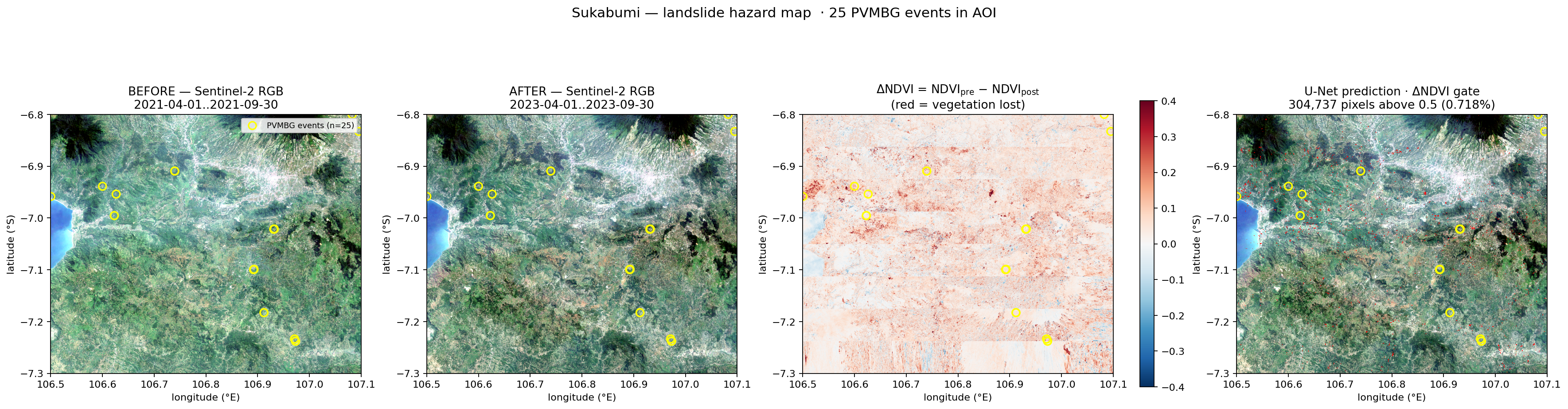
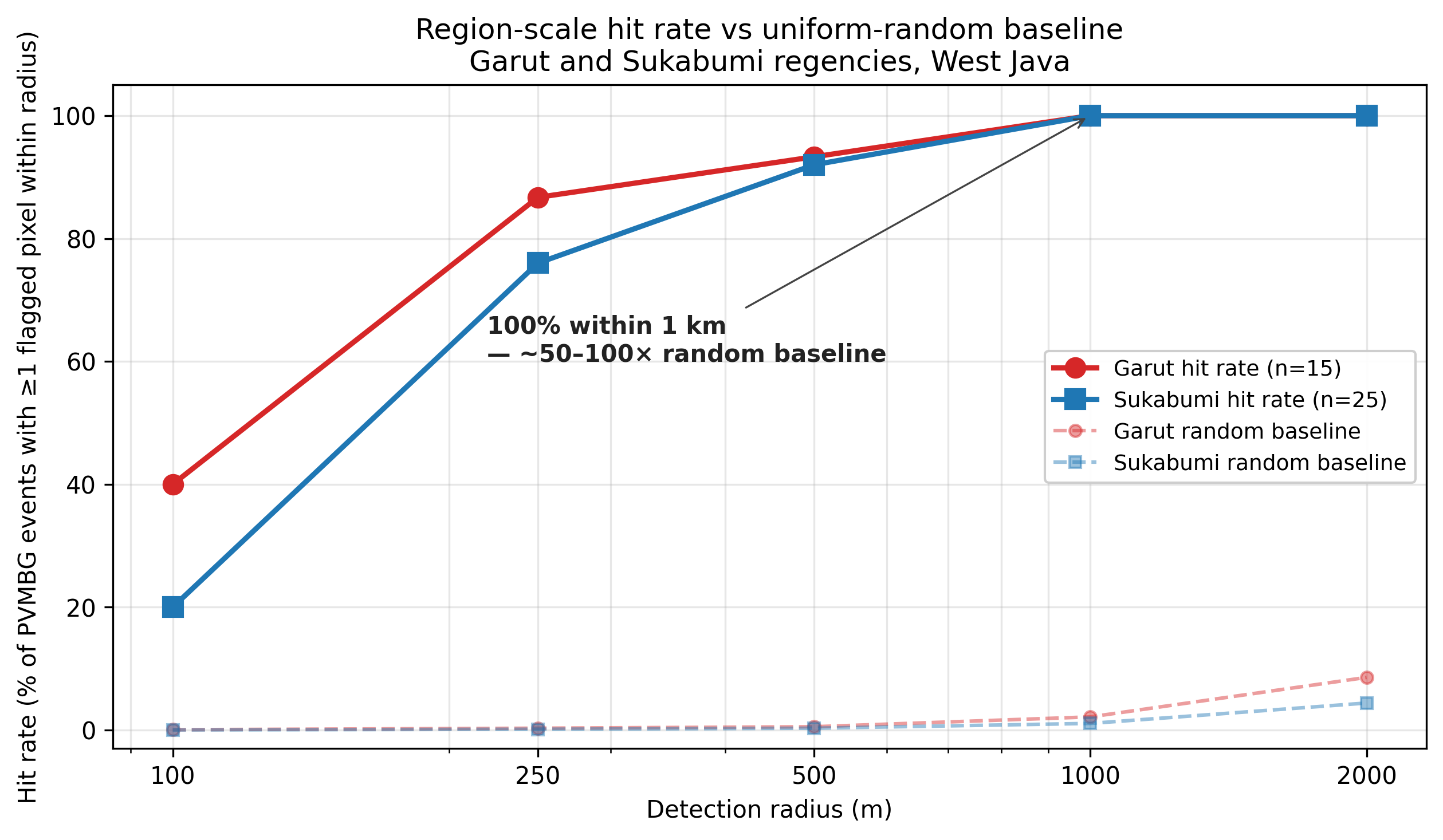
Phase 1 — Both baselines land in range
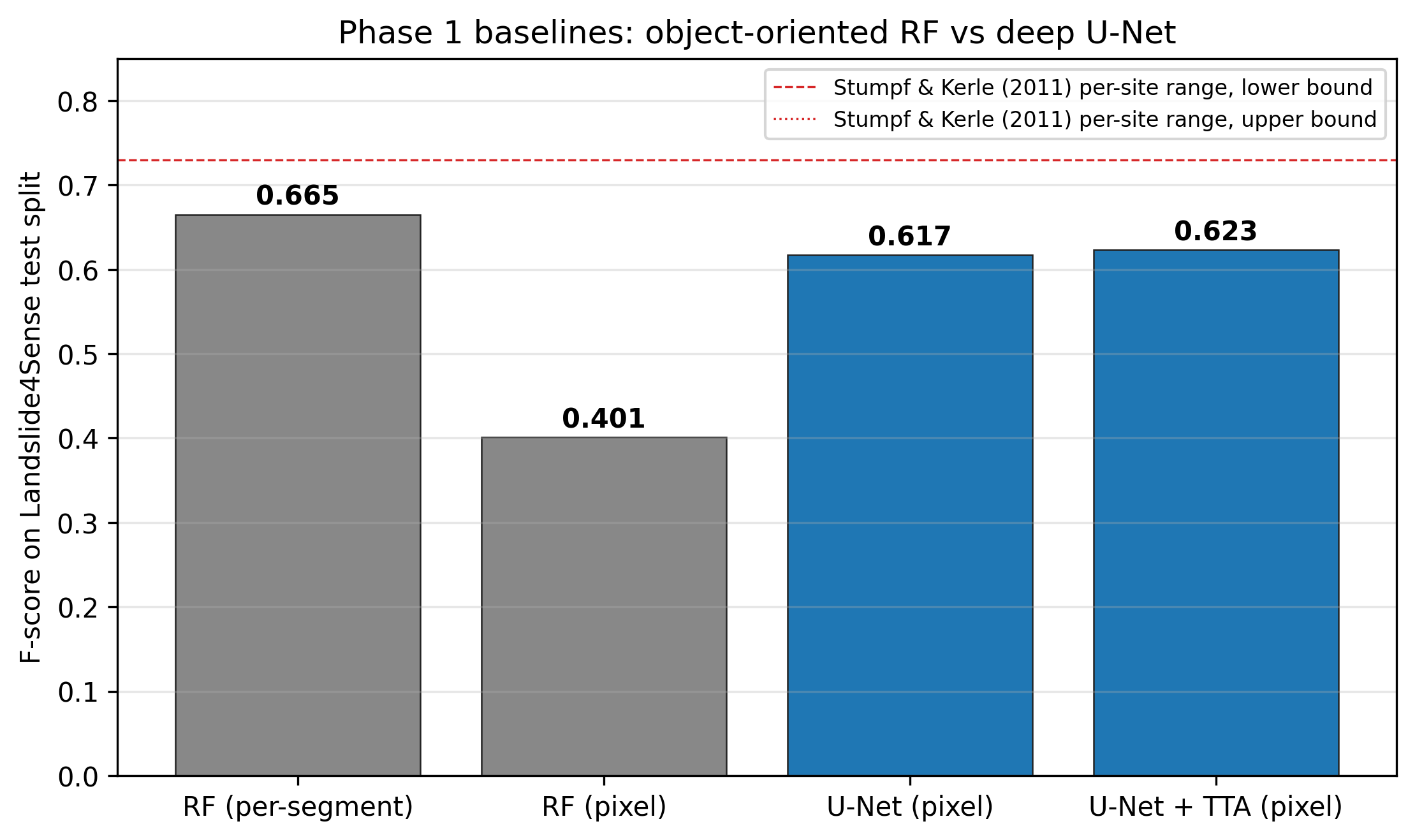
Fig. 1. F-scores on Landslide4Sense. RF baseline reproduces Stumpf & Kerle's per-segment range; U-Net wins on pixel-level by +22 pp.
0.665
RF F (per-segment, test)
0.766
RF F (val, in S&K range)
0.617
U-Net F (pixel)
0.623
U-Net F + TTA
- RF/OOA pipeline replicates Stumpf & Kerle's 0.73–0.87 paper range on validation
- U-Net (ResNet-18 ImageNet pretrain) beats RF on pixel-level F by 22 pp
- Models are validated on the native benchmark before any cross-region deployment